这篇文章是系列文章的一部分,我在这里公开构建一个Web应用程序。它被称为Lumeno,您可以在Twitter上跟进其开发 - @LumenoDev 或者 注册 以在它推出时收到通知。
在构建Lumeno的过程中,我花了一些时间去研究处理大型数据库及其应用程序的注意事项。这对于我来说特别重要,因为Lumeno有可能变得相当大,我不想过多地担心(关于)扩展问题。
关注现实
我认为作为开发者,我们往往假设我们构建的任何东西都将变得庞大,我们不可避免地将会处理扩展问题。简单(可能是令人悲伤的)的事实是,对于我们中的99.9999%,这一切都不会发生。您的应用程序将保持小型或中型的大小,技术扩展问题不会成为您仅通过升级服务器规格就无法解决的问题。
好吧,但如果你属于那0.0001%?如果是这样,你几乎肯定会处于以下两种情况之一
场景 #1
您的应用程序将缓慢稳定地增长。如果是这样,您将能够使用监控工具在早期就发现扩展问题。这将为您留出时间来制定处理扩展的策略。如果您的增长发生得更加爆炸性,您始终可以投入资金改善服务器配置以争取时间,或者考虑迁移到类似 PlanetScale 的可管理扩展服务。只是请注意,这些服务的价格可能会让人惊讶(基于行读取量),一些事物通常是缺少的,例如外键/级联删除等。
场景 #2
另一种情况是您从第一天开始就有大量的增长。有很大可能性,只有当您是一个知名实体,可能会吸引大量关注的时候才会发生,例如 Google 发布某项产品。如果是这种情况,并且您正在阅读这篇文章,那么您的数据层策略几乎肯定是由拥有大量应对扩展经验的人处理的。您会被告知该做什么/使用什么,所以您不需要担心。
选择您的数据库
现在有大量的数据库系统可用,但我将重点关注大多数Web应用程序使用的那些:MySQL 和 Postgres(SQL Server 也是候选之一,但由于我不用它,因此在此不进行引用)。
让我们看一下您在选择数据库系统时需要考虑的因素。
性能
过去,MySQL 和 Postgres 之间存在明显的差距。当 MySQL 使用 MyISAM 引擎时,它在写入时的速度比 Postgres 慢,但在读取时速度要快得多。然而,MyISAM 不包括许多关键特性,如事务,这就是为什么我们现在使用现代的 InnoDB 引擎。
在撰写本文时,MySQL 和 Postgres 的最新版本在性能上几乎相当。在基准测试时,您可能会发现一些差异,但在实际应用中您可能不太会发现太多差异。
特性
毫无疑问,Postgres 在这方面是赢家,因为它包含了大量您可能发现对应用程序非常有用的其他功能。
我不会深入介绍 Postgres 提供的额外功能(太多了),网上有成千上万的文章进行比较,但简单地说,除非您的应用程序需要 Postgres 的功能,否则您应该可以使用任一数据库系统。
可扩展性
人们喜欢问,“它会扩展吗?”这不仅关乎数据库。我拒绝卷入这场火焰战。简单回答,是的,它们都可以扩展。
想证明吗?Instagram 使用 Postgres。Facebook 使用 MySQL。
同样重要的是要注意,无论哪种系统,拥有大规模扩展的大多数公司很少使用原始数据库代码。相反,他们已经分叉了原始项目并进行大量更改以满足他们的需求。
支持
MySQL 肯定更受欢迎,因此拥有更多的数据库管理员,这使得获取支持或雇佣都更容易。话虽如此,Postgres 发展得很快,它不再像以前那样是一个问题。
然而,Postgres 的一大反例是,如果您想使用共享托管,那么您将很难找到提供此服务的公司。请注意,到了可扩展的程度,您不会使用共享托管...
总结
在大多数情况下,选择哪一个并不重要。
值得一提的唯一事情是,尽管这两个系统都是围绕 SQL 标准构建的,但它们并不是彼此的即时替代品。如果您打算更换,您将需要做一些工作。然而,如果您依赖于 Laravel 或更具体地说 Eloquent 来处理数据库交互的繁重工作,那么工作量不会太大。
一些需要注意的实际扩展事项
在本节中,我将讨论一些常见的扩展想法和问题。在某些情况下,我会提醒注意事项。在其他情况下,我会消除一些你可能不应该使用的方法。
不言而喻,由于我正在撰写的是一部著作而非专著,因此本节将对内容进行总结。但请注意,这些主题涉及大量细节和微妙的差异,因此请确保从其他来源学习以获得更全面的理解。
特别感谢Jack Ellis、Tobias Petry、Kevin Hicks等人提供的见解,这些见解构成了本节的一个重要部分。
1. 你可能不需要使用UUID、分片或其他复杂的设置
有些人反对将自增ID用作主键,但在大多数情况下,它们完全胜任工作,尤其是在每秒处理多达~1000个写入操作时。如果你发现你正在处理更多的操作,那么你可能需要考虑像Twitter的Snowflake这样的解决方案,但如果你可能的话,应该努力避免这些引入复杂性。
如果你不能使用自增,那么你可能已经有了需要重构你的数据层的其他问题。在这个时候,你可以改变创建唯一主键的不同方法。
作为一个替代方案,可以考虑在你的应用程序中实现一些基本的错误处理/使用
retry辅助程序来处理可能由自增过程引起的任何死锁。
2. 简单的写入查询通常不是问题
继续第一点,应该强调的是,运行简单的查询通常不会引起自增死锁的问题,例如
INSERT INTO `users` (`name`) VALUES ('John')
相比之下,运行缓慢/批量写入查询可能会遇到问题。例如
INSERT INTO `users` SELECT * FROM `temp`
在这种情况下,最好使用Laravel分批执行这些写入操作,并依靠错误处理重试失败的操作。
3. 当整数可以满足需求时,避免使用字符串
可能会诱使用字符串常量,例如用于用户角色的(管理员、员工、客户),并将它们作为字符串存储在数据库中,以使其更易于理解。
不幸的是,数据库引擎在字符串方面的速度并不快(即使它们已经索引)。相比之下,整数要快得多。在上述例子中,可以使用数字,例如管理员 = 1,员工 = 2,客户 = 3。
如果你真的想使用字符串,那么请考虑使用枚举,因为这些允许使用字符串值,但它们被视为整数进行索引。但请注意,枚举是固定的,所以如果你需要添加更多选项,你需要更新你的表结构,这可能对于大型表来说是一项成本较高的操作。
避免使用带有通配符前缀的WHERE LIKE
当你执行以下查询时
SELECT * FROM `users` WHERE `name` LIKE '%john%'
即使name列已索引,MySQL也需要进行全表扫描。如果你绝对必须这样做,请通过包括可以也使用索引的额外WHERE子句来尽可能限制可能的结果,例如
SELECT * FROM `users` WHERE `organization_id` = 1 AND `name` LIKE '%john%'
Kevin还指出,“除了包括可以使用索引的WHERE子句外,还必须确保为最常见的查询正确设置索引。跨多列的索引可以帮助确保查询的正确性。例如,如果查询将查询多个列A和B,则对于这两个列的索引可能会有所帮助。”
但请注意,如果索引太多,或者索引与正在运行的查询不匹配,那么无法保证数据库实际上会使用这些索引,或者使用用于查询的最佳索引。
最后,应注意的是,如果你删除前缀并只使用后缀,那么MySQL可以使用索引,例如
SELECT * FROM `users` WHERE `name` LIKE 'john%'
或者,您可以选择Postgres,它包括三叉支持。这使得您能够相对高效地进行首次查询,因为它通过将name列中的值分成3个一组来构建索引,例如对Alice来说,您会得到{ali, lic, ice}。您可以在这里了解更多信息
https://about.gitlab.com/blog/2016/03/18/fast-search-using-postgresql-trigram-indexes/
5. 全文搜索可能是答案,但有一些注意事项
继第4点之后,如果需要进行通配符搜索而且不够快,那么用全文索引和搜索来替换可能有所帮助。但请注意,根据MySQL文档,这可能会在向表中写入时产生副作用
对于大型数据集,在没有全文索引的表中加载数据再创建索引,比在已有全文索引的表中加载数据要快得多。
6. 事务不是敌人
事务在需要执行多项任务并且能够回滚失败的任务时非常有用。不幸的是,它们可能会导致死锁(在某些情况下)。尽管如此,还是有方法可以减轻这种情况的。
Tobias指出,“如果没有显式启动事务,每次写入操作都隐式地是一个单独的事务。所以,如果你做了3-4次写入操作,你就有了3-4个事务,每个事务都有一些写入操作作为开销。单一事务更有效率,因为写入操作是被捆绑在一起的。”
您还可以在应用程序内部尝试重试,以在死锁事件中重新运行事务。
虽然死锁很令人烦恼,但在努力提高性能或消除问题的同时跳过事务通常不是一个好主意。在99.9%的情况下,应用程序不是设计来处理可能导致数据损坏的局部失败的。您必须确保它们完成。因此,您需要事务。
7. 使用事务时,考虑使用保存点
对于耗时较长的交易,考虑使用保存点。把它们想象成游戏里的保存点。你保存了,如果你失败了,你可以回到保存点。
使用保存点可能是一个更容易解决问题的方法,而不是尝试预先计算可能出现的每一个错误条件。相反,你可以让数据库来处理这些问题。
这里有一篇文章,用一些简单的图表很好地解释了这一点
8. 减少死锁超时
如果您仍然遇到问题,可以使用以下命令在MySQL中减少死锁超时
SET GLOBAL innodb_lock_wait_timeout=100
提供的值以秒为单位。最小值为1,默认值为50,最大值为1073741824。
对于Postgres,您可以使用以下命令
deadlock_timeout=1000
提供的值以毫秒为单位。最小值为1,默认值为1000,最大值为2147483647。
为什么你想降低它?这样可以使死锁更早解决,请求可以再次内部执行。
9. 确保您的服务器有大量的存储空间
我们大多数人都会想到确保数据库有足够的CPU和RAM资源可用,但很多时候我们忽略了存储空间的大小。即使数据库本身相对较小,例如1-2 GB,您的服务器仍然需要大量的存储空间,因为它涉及到IOPS(每秒输入/输出操作)。
我不会过多地详细介绍(因为我对其了解不多),但如果您对此感兴趣,Jack Ellis写了一篇关于IOPS及其重要性的大博客文章。阅读它在这里
处理应用程序中的大量数据
现在,让我们看看如何在Laravel应用程序中处理大数据集。我们将从读取和写入两个方面来处理。
读取大量数据。
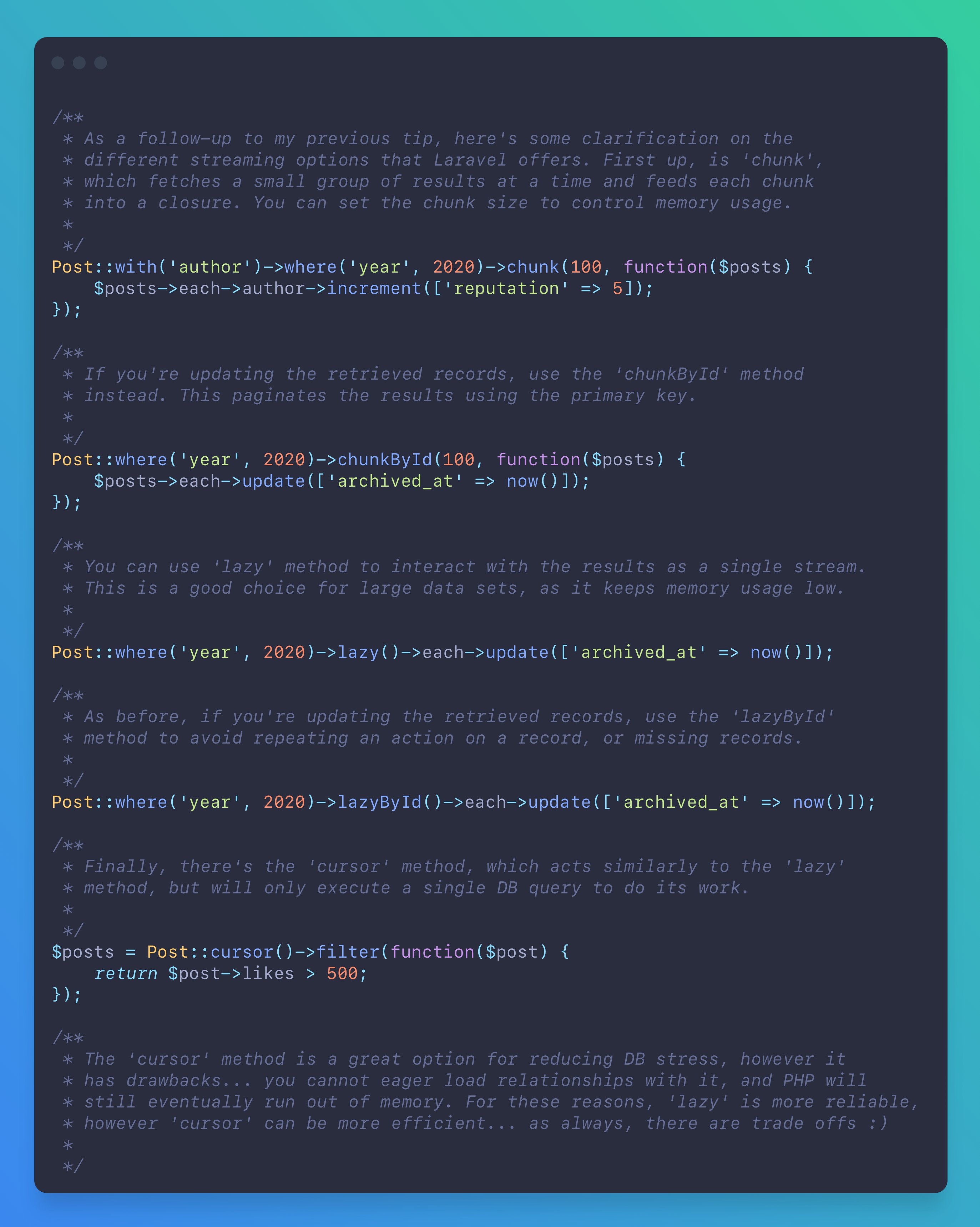
正如您所期望的,答案是分页。Laravel提供了3种类型:标准、简单和游标。
标准分页
当进行大规模操作时,标准做法因多种原因而不再适用。首先,它需要执行两次查询(第一次获取页面,第二次获取总行数)。其次,因为它使用了LIMIT和OFFSET,当用户滚动到第20、30、40、50页时,查询会越来越慢。
简单分页
这要快得多,因为它只使用一个查询(不计算行数)。然而,它仍然使用LIMIT和OFFSET,但是在您的Blade视图中渲染时,它只提供上翻和下翻按钮,因此人们不太可能跳转到高页码,因为他们必须先滚动过前面的页码。他们技术上仍然可以使用查询字符串跳到高页码,但由于UI没有提供,所以可能性较小。
游标分页
这是一种较新的方法,也是最有效的。与其他方法相比,它在查询中比较排序列中包含的值的WHERE子句。这使得它非常适合大数据集。
但它也有一些限制……您不会得到页码(如标准分页中所示),您的查询需要排序至少基于一个唯一列或唯一列的组合。不支持的列具有null值。最后,“order by”子句中的查询表达式仅在它们有别名并添加到“select”子句中时才受支持。
如果您能够在这些限制下工作,那么在大规模操作中的性能将会有明显提升。
在大数据集中进行遍历时的编写
对于本节,我将简单地参考我在Twitter上发布的关于您可用的每个选项的技巧。每种方法都有优点和缺点,应在做出选择时考虑。
应该注意的是,这些示例故意很简单,以便传达这个点。实际上,您可以通过单个查询完成这些示例中实际完成的所有事情,但是您已经理解了这个观点。
总结
如果您想跟随我创建Lumeno的旅程,并了解我如何克服到达那里的其他编码挑战,那么为什么不关注我的Twitter?您可以在@mattkingshott找到我。
如果您想了解Lumeno何时发布,您可以在其网站上注册。
感谢阅读,祝您度过美好的一天 🙌🏻
driesvints,tomhatzer,mkhleel,behzodjon,alexanderf 点赞了这篇文章








 Laravel
Laravel  Laravel News
Laravel News  Laracasts
Laracasts  Laravel Podcast
Laravel Podcast